Appendix 3:
River Reach Definition
Splitting the river network into homogeneous habitat reaches using river segmentation technique.
Rivers were split into reaches using a segmentation approach based on spatial similarity for a series of indices representing habitat structure. The approach consists of selecting a series of indices or attributes to represent channel morphology that are modelled and predicted using map-derived attributes such as slope, discharge, land use etc. The models are then implemented at regular intervals (e.g. every 500 m) along the river network. The predictions for contiguous river sections are compared and clustered using a statistical spatial clustering algorithm so as to maximise the variance between clusters and minimise the variance within clusters (or reach). Clusters can then be aggregated in the shape of river reaches whose variability can be described and predicted.
For the derivation of river reaches for ToolHab, habitat was defined as a combination of four structural elements: channel substrate, flow regime, erosion and deposition patterns and channel vegetation structure. River reaches were defined as homogeneous stretches of river with regards to the four structural elements as observed and as they would be in natural or near-natural conditions. The four habitats structural elements were derived using field data from the River Habitat Survey (RHS). The RHS is a methodology for recording habitat features that has been applied to more than 25,000 500m river sections in England and Wales since 1994 (Raven et al. 1997). The survey is organised in two major sections: 'spot-checks' and 'sweep-up'. The spot-checks are a series of ten 1 m wide transects across the channel at 50 m intervals, where bank and channel physical structure, as well as man-made modifications, land uses and vegetation structure, are recorded in a replicable manner.
Spot-check data on channel substrate, flow types, erosion and deposition features and channel vegetation were collated in four separate tables showing the occurrence of individual features (e.g. for channel substrate, the individual substrate types: bedrock, boulders, cobbles, gravel pebbles, sand, silt, clay, peat and artificial) across 10 spot-checks for existing RHS semi-natural sites. A semi-natural site is defined as a site with little or no signs of man-made modifications to the channel or the banks (Raven et al. 1997). The tables were analysed using Correspondence Analysis to extract the most important dimensions that were used as indices for describing the four habitat structural elements.
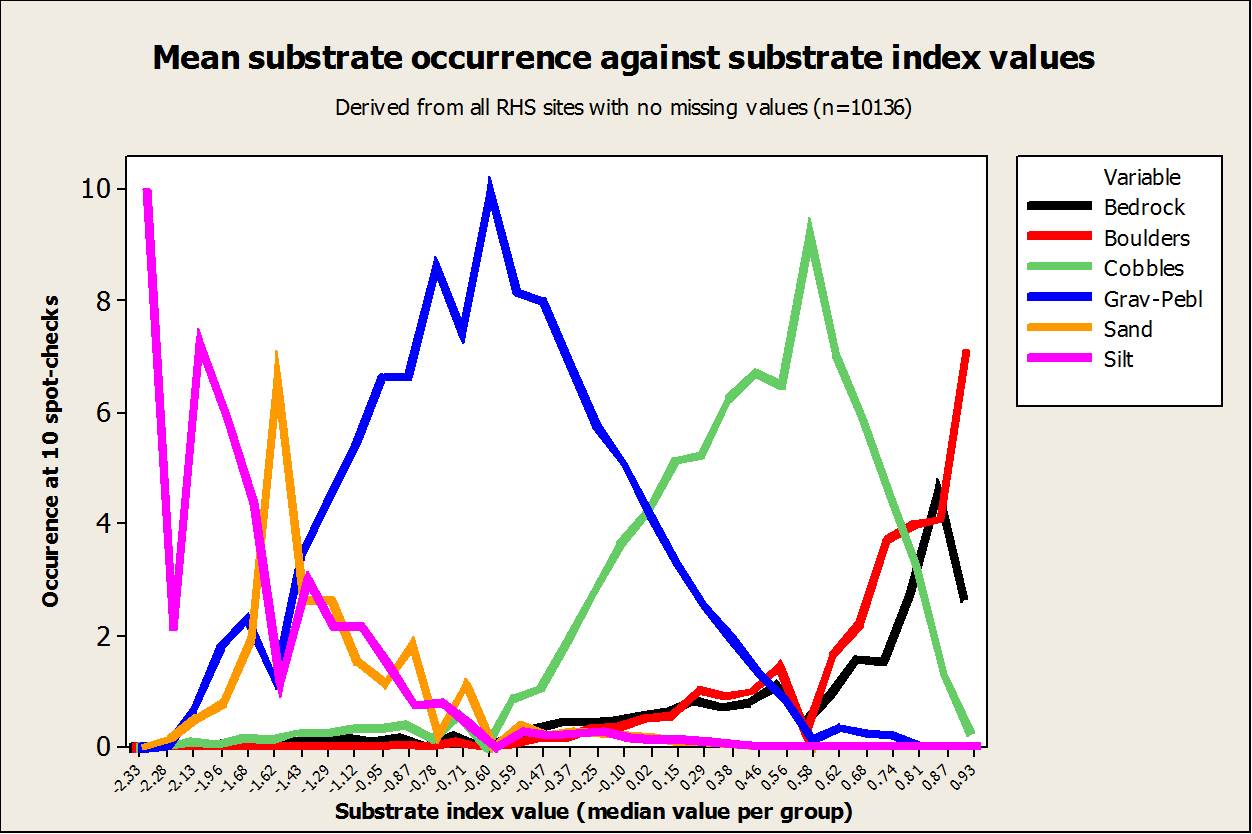
One of the four indices, the Channel Substrate Index (CSI) is represented in the figure below. The chart was derived for a subset of 1881 semi-natural RHS sites with no obvious signs of modifications and no missing values. The sites were grouped into 31 bins based on their CSI index value and the chart displays, for each bin, the average occurrence of 7 channel substrate types. Finer sediments dominate on the left hand side of the chart (larger negative CSI). The CSI describes a gradient from fine sediment dominated rivers to coarse sediment typical of a upland-lowland shift in substrate size with increasing distance to source and accounted for about 20% of the total variability found in the data. The other indices described similar gradients.
The 4 indices were modelled against a series of GIS attributes using linear regression best subset selection procedure and tested using a jack-knife cross-validation technique. The models were spatially corrected using a series of methods. A simple methodology was to reiterate the existing model and add additional variables representing the index value for the closest RHS on the river network along with the site distance and its location upstream or downstream. Another method was to perform geostatistical analyses on the main model residuals (Bivand et al., 2008). The outputs from all models were compared and the best models were selected.
Two sets of predictive models were derived for the four structural elements indices: one predicting habitat structure as observed during field survey and one predicting habitat structure as it would appear if the sites were semi-natural. The first model set was produced using all existing RHS sites, whether modified or not, and the second set was produced using only semi-natural sites. The R-square values for the best models are presented in the table below.
Amongst the four indices, the Channel Substrate and the Flow indices had the highest level of predictability with R-square at 68% and 56% respectively. The model for channel vegetation and activity in comparison explained 48% and 42% of the variability. Predictions for semi-natural sites showed similar levels of predictability despite the much reduced sample sizes. Spatial corrections brought about slight to moderate increases in predictive ability for the Channel Substrate, the Flow and the Activity Indices and quite significant improvements for the Channel Vegetation Index. Altogether, the predictive ability of the index value models was satisfactory.
Predictive models produced using all sites |
Predictive models produced using semi-natural sites only |
|||
Indices |
Main model |
Main model with spatial component |
Main model |
Main model with spatial component |
Channel Substrate Index |
68% n = 9492 |
70.4% n = 5857 |
66% n = 1759 |
70% n = 604 |
Flow Index |
55.9% n = 12983 |
61% n = 8282 |
53.6% n = 1997 |
67.2% n = 889 |
Channel Vegetation Index |
47.9% n = 11196 |
58.7% n = 7811 |
52.2% n = 2036 |
67.6% n = 853 |
Activity Index |
42.4% n = 12870 |
47.8% n = 9261 |
35.3% n = 2140 |
44.3% n = 986 |
The spatially corrected predictive models were applied to all 500 m sections on the 15 rivers part of the DSS to predict observed and semi-natural values for all four indices. Adjacent 500 m sections were grouped using a spatial clustering freeware called VAST (Brenden et al. 2008). VAST was designed for clustering contiguous river segments based on their similarity with regards to attributes or indices and their spatial position within the river network. VAST offers a series of options for clustering river sections. Clustering can be performed starting from the top of the river or the bottom or it can be done randomly or based on similarity levels using various distance measures, linkage methods and affinity threshold values.
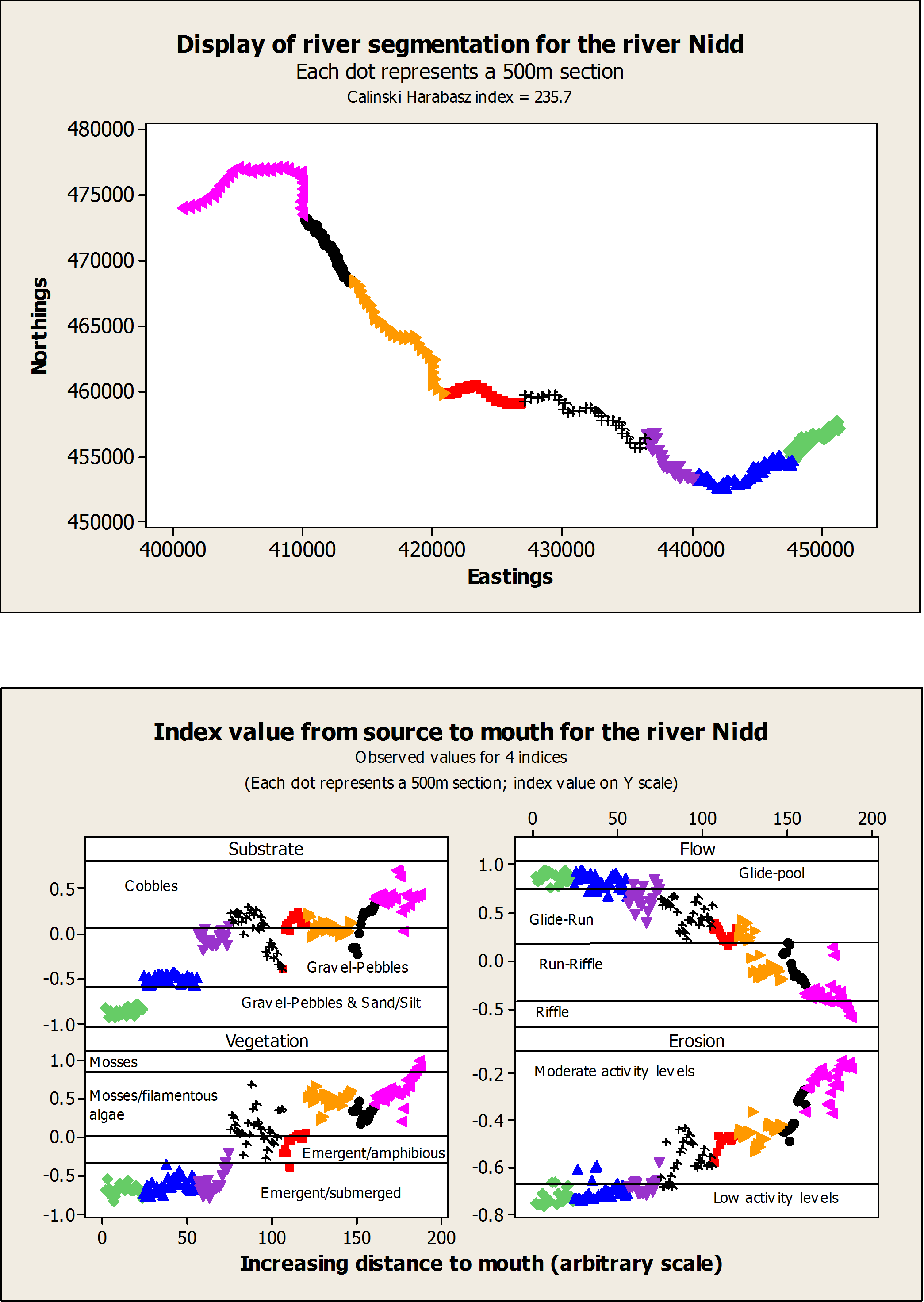
Each river was clustered by running the VAST algorithm using various combinations of options. The outputs were assessed using the Calinksi and Harabasz (1974) index (CH index), a ratio that compares variance between and within clusters. The fours indices were also plotted against the distance to source so as to allow visual checks and the identification of the most optimal solution. Sometimes, clustering was corrected following visual checks when obvious breaks in structural elements index values had been missed out by the clustering algorithm. An example of clustering is shown in the figures below. The first figure shows the best cluster combination found using VAST and the CH index. The second figure shows the distribution of the 4 index values for each 500m point and cluster (in colour) from source to mouth.
The sections within each cluster were aggregated into river reaches using GIS ArcView. The resulting maps were circulated to Environment Agency staff for comments as Google Earth kmz files and in pdf format.